前面花了許多篇幅在討論如何使用不同類型的推薦系統預測,問題是我們要如何評價他們的優劣呢?
假設我們要向一個家長推薦商品,假設圖中的商品就是我們所有的商品了,而有紅色框框的則是家長所喜愛的

我們的目標是,從他購物的行為發現他的喜好
此時有一個問題是,那我們直接用分類精準度(喜歡/不喜歡)來判斷他的模型好壞就好了不是嗎?
這邊必須澄清我們確實關注使用者喜歡什麼?但是問題是,與他的喜歡相比,另一個分類明顯佔了多數
記得E-mail那個例子嗎?在那個例子之中,我們只要全部都猜是垃圾郵件就能有90%的命中率了,因此在這個例子之中,我只要推測所有的商品都是使用者不喜歡的,此時我的精確度就可以達到非常的高
在現實的世界中,我們會假設使用者關注的時間其實是有限的,所以我們也只會推薦有限的商品
今天我們要選出一小部份來推薦給別人,是要花非常大的成本,而若是推薦的東西不是使用者喜歡的成本則更大(花了一堆時間做白工)
所以我們會討論另一種評量推薦系統好壞的方式,我們稱之為"Recall"與"Precision"

#Recall:(喜歡的商品 & 推薦給你的商品) / 所有你喜歡的商品
Recall = 3/5
#Precision:(喜歡的商品 & 推薦給你的商品) / 推薦給你的商品
Precision = 3/11
所以 Recall 量測的是,我們推薦的商品覆蓋率有多高,而在討論 Precision 時就得關注所有推薦的商品,這些商品中有那些是使用者喜歡的
換句話說,當我們在說 Precision 時,它透露的含意就是跟喜歡的商品相比使用者必須看多少我不感興趣的商品
此時我想問,我們該如何讓 Recall 最大化?
其實一點都不難,只要推薦所有商品就能夠達到百分之百了,但此時你的 Precision 就會變得很小
那最好的推薦是怎樣的呢?在"Recall"與"Precision"都為1的理想狀態下,理所當然推薦了所有使用者喜歡的商品,並且所有推薦裡面都是使用者喜歡的
現在我們來看看如何評估"Recall"與"Precision"
為了進行比較我們畫了一個叫 precision recall curve 的東西,我們先來談談曲線在當中代表的意義
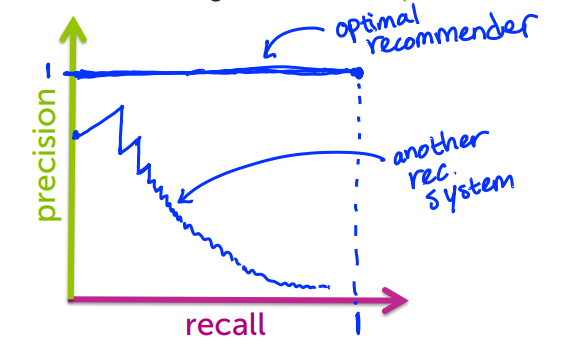
我們對系統輸入不同的 threshold 改變系統可以給我推薦的數目,舉個例子,在網購平台上我想要你推薦一件、兩件甚至是三件或以上的商品,這就是我們要改變的 threshold ,只要沿著曲線就能找到
最佳曲線(藍色)是什麼樣子呢?就是只推薦我喜歡的
假設我有十件喜歡的商品,你只推薦一樣我喜歡的,此時 Precision 為1,但 Recall 只有0.1,但是隨著我的推薦個數增加 Precision 也將趨向1
但是實際上的曲線(粉紅)會是什麼樣子呢?第一個商品可能是我不喜歡的,隨著 threshold 的增加我的 Recall 和 Precision 也會增加,但又會在 threshold 的值增加到某種程度後往下走,可以想見最終我的 Recall 可以到達1但是 Precision 會下降
現在我們已經知道該怎麼畫 precision-recall curves,那該如何運用它來評價推薦系統呢?
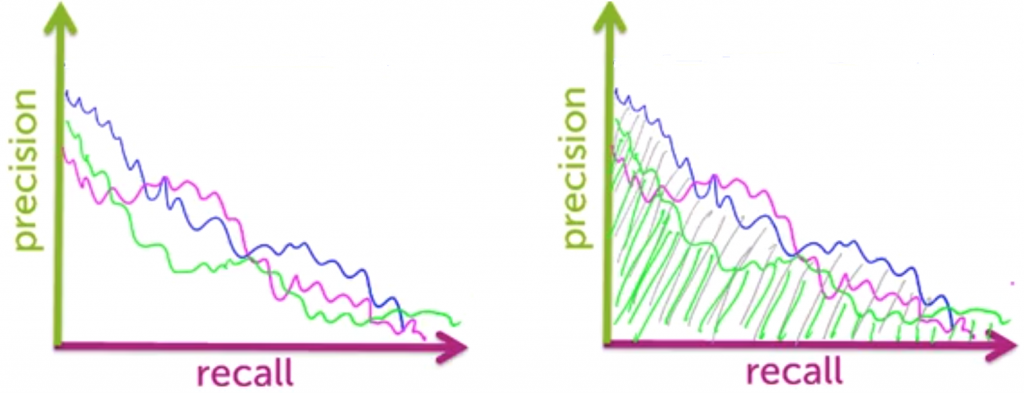
與理想中的推薦系統相比,真實的系統會趨近於上圖的曲線,我們希望 Recall 和 Precision 盡可能的變大,有一個直觀的方法
我們只要考慮曲線下方的面積就可以了,面積大的曲線表示其 Recall 和 Precision 更高
在真實世界的推薦系統其顯示有極限,你不可能在一個網頁裡面把所有的商品一口氣顯示出來,因此再有侷限的命題裡,你所要關心的是在這個 threshold 之下誰的 Precision 好,畢竟覆蓋所有使用者喜歡的商品,在演算法中所要耗費的成本太高
在這個模型中我們討論了協同過濾的概念和一系列不同的推薦系統,讓我們透過別人的購買紀錄來推薦商品,我們研究了消費者和商品在推薦系統下他們之間的關係
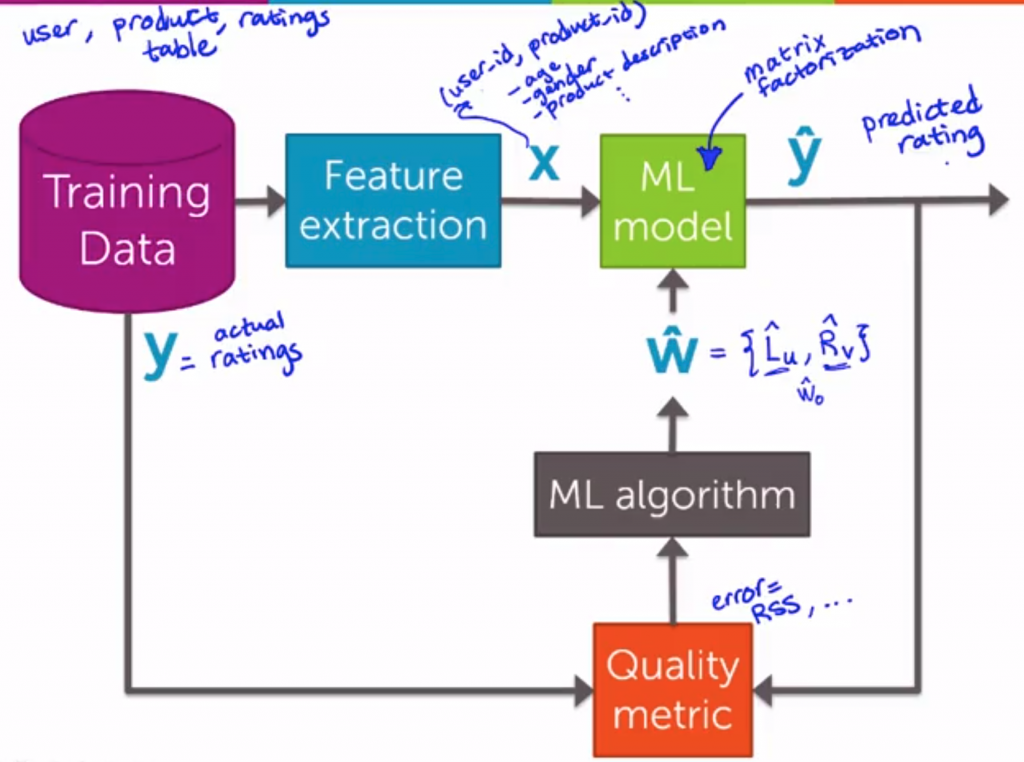
同樣的我們要來回顧一下 Recommender system 的 work flow



 iThome鐵人賽
iThome鐵人賽